
10 Introduction to Modeling
Learning Objectives
- Explain modeling steps
- Describe modeling design
- Define modeling principles
- Describe strengths and weaknesses of modeling techniques for decision making
Chapter content
Modeling steps
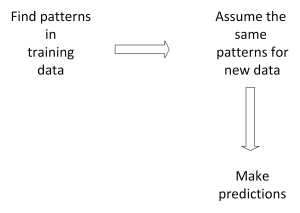
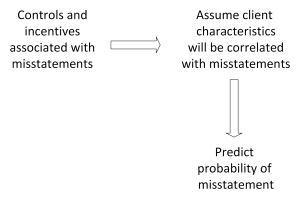
Modeling design
Model algorithm
Technical details for modeling design
The details for how the algorithm is applied depend on the model. Here we will walk through two examples of how the algorithm for a supervised learning model could be applied. We will first be general and then we will be more specific.
General
Specify a pattern
The first step is choosing a pattern that a model should identify. Patterns in the data tell us the expected associations between predictor and outcome variables. Because there may be random causes of the outcome variable, the expected associations tell us what is typical based on the variables and patterns we observe. Note that we expect to be wrong because we will not be able to perfectly model the outcome variables.
A pattern can be identified with specified data and parameters. For example, the data could be a vector that contains company age for a set of 100 companies and another column that contains number of employees for the same companies. A parameter could be the correlation between company age and number of employees. For example, this might be a correlation 70% saying that the age of the company is 70% correlated with number of employees.
A general form of this could be stated as follows, where X is a data matrix made of up x for entity i at time t, β is a set of parameters, and Y is a vector of outcomes y for entity i at time t that we want to model.

This general form means that we have an observed outcome Y that we want to explain or predict. “fun” indicates that whatever pattern we do find is a function of the data X and the parameters β. The parameters β are unknown. We will use the data to estimate them.
Define fit
From this general model, we need to determine what makes the model a good fit for the data. Because the data X is already given, we only have β to work with. A measure of model fit defines for the algorithm what a good set of βs are. Define a prediction from the model as  . This means that whatever pattern we find using the β and X, the predicted vector of outcomes is given by . There are different ways to define fit such as mean absolute error or r-squared. The specific way to define fit is not important here, but we will use mean absolute error (MAE) to discuss it.
. This means that whatever pattern we find using the β and X, the predicted vector of outcomes is given by . There are different ways to define fit such as mean absolute error or r-squared. The specific way to define fit is not important here, but we will use mean absolute error (MAE) to discuss it.

This measure of fit compares the predicted value for each observation  with the actual outcome
with the actual outcome  . The absolute value of the difference is a measure of how close the model prediction is to the outcome. Summarizing across all predictions and outcomes, in this case using the mean of the absolute error, captures a summary of how the model fits observations across all outcomes. Another common way to summarize the fit include summing the squared value of the errors (mean squared error). The larger the MSE, the worse the model fits the observed outcome.
. The absolute value of the difference is a measure of how close the model prediction is to the outcome. Summarizing across all predictions and outcomes, in this case using the mean of the absolute error, captures a summary of how the model fits observations across all outcomes. Another common way to summarize the fit include summing the squared value of the errors (mean squared error). The larger the MSE, the worse the model fits the observed outcome.
Find the parameters that maximize fit
With the pattern selected and the fit defined, model estimation involves choosing the parameters that best fit the data. This might take the following form.

This optimization sets the objective to minimize MAE, i.e. maximize model fit, by choosing the β parameters.
Returning to the modeling steps, once the model is estimated on training data, the model, now with βs set based on the training data, the parameters are assumed to be applied to a different data set. For example, Z rather than X. In this case, the βs are combined with Z to make predictions for the new data set.
Specific
| Row ID | Fine Amount | Fraud Damage Amount | Prior Fraud Committed | Company Size |
| 1 | $300 | $500 | 0 | $25,000 |
| 2 | $1,550 | $750 | 1 | $100,000 |
| 3 | $725 | $1,000 | 0 | $15,000 |



 ,
,  , and
, and  , to determine the fine amount. We might make this more specific with the data example above.
, to determine the fine amount. We might make this more specific with the data example above.| Fine Amount | Fraud Damage Amount | Prior Fraud Committed | Company Size | |||||||||
| $300 | = | β1 | $500 | + | β2 | 0 | + | β3 | $25,000 | + | ε1 | |
| $1,550 | = | β1 | $750 | + | β2 | 1 | + | β3 | $100,000 | + | ε2 | |
| $725 | = | β1 | $1,000 | + | β2 | 0 | + | β3 | $15,000 | + | ε3 |
Modeling definitions and principles
Training data
Testing data
Assumption that patterns apply to new data may be wrong
The risk from applying patterns to new data is significant and we use methods to try to reduce that risk. After using the training data to develop our models, we move to predicting outcomes. We take the same structure to new data where we do not observe the outcome to predict what we think it would be based on the model we estimate on the training data.
How well the training data model predicts outcomes on new data depends on many factors. The following outlines some of the biggest concerns.
Another concern is the interpretation of patterns in data. Correlation is a statistical property of how two (or more) variables move together. Two variables can move together because one variable causes the other. For example, dropping a ball from varying heights causes the ball to bounce higher. Two variables could also move together because a third variable causes them to move together. The third variable may be part of the causal chain relating the two variables, for example, the force the ground exerts on the ball when it hits causes the ball to bounce. In this case dropping the ball might be said to cause the ball to bounce even though it is not the proximate cause. The third variable may be not related to the causal chain and in this case the correlation between the first two variables is only driven by a spurious correlated variable. Alternatively, two variables may be correlated by chance. These correlations then are spurious and imply no form of causation.
Some practices help limit the impact of these problems in modeling. These include:
- Be careful and think critically before analyzing data.
- Only work with training data that is representative of the population of interest.
- Keep testing separate and only use it once after all model development is complete.
Applying models to decision making
Data analysis is useful if it informs decision making. Empirical models can inform decision making in at least two ways. First, modeling may uncover patterns in data that inform how decision makers think about problems. For instance, a model might show the accounts that are most commonly associated with fraud. The model therefore informs how decision makers think about controls or detecting fraud. Second, modeling may provide useful predictions. For example, predicting which individuals most likely avoid taxes informs IRS decision makers about how to allocate time and resources.
In addition to the concerns from the previous section, whether modeling is useful for decision makers depends on many factors. Some of the strengths and weaknesses of modeling tools are listed below.
Strengths
- Can include many variables that affect outcomes.
- Can include interactions, non-linearities, or other complex associations.
- Can synthesize information from large data sets.
- Effectiveness of predictions can be tested.
- Can be designed for specific questions and problems.
Weaknesses
- Requires data to train a model.
- A model may not be a good representation of reality.
- Data may not contain outcomes or important predictors.
- A good training data model may not generalize to new data.
- Model may not directly address what decision makers need.
Conclusion
In this chapter, you learned about the model process, modeling design, and modeling principles. You also learned about the strengths and weakenesses of modeling as a data analysis tool.
Review
Mini case video
References
Ellenberg, J. (2015). How not to be wrong: The power of mathematical thinking. Penguin.
Ioannidis, J. P. (2005). Why most published research findings are false. PLoS medicine, 2(8), e124.
<http://www.tylervigen.com/spurious-correlations>.
Media Attributions
- Drawing 3
- Drawing 3 (1)